2021/02/09 - [공부/파이썬] - [파이썬] 1일차 - 개발환경 설정, 기초
지난 시간 디버그, 디버깅..
폴더 210210_011 > 파일 Debug_00.1py
디버그의 기능 : 프로그램이 잘 실행되고 있는지 확인하는 것! -> 프로그램이 순차적으로 수행되는 것을 알 수 있다 -> 숨어있는 버그를 찾는 것은 (문제가 있는지 아닌지는) 프로그램을 만드는 사람이 판단해야 함

저 빨간 점이 break point ! 저기서부터 디버깅 시작함
- 내가 지정해준 4번 라인부터 디버깅이 되기 때문에 Debug를 누르면 그 윗부분 1~3까지는 이미 실행이 되었고,
4번에서부터 정지된 상태로 나옴 => 그래서 break point라고 함!
그러나 현재는 1~3이 주석, 빈내용 이므로 상관없음!

[F11] 누르면 한 줄씩 실행이 되고, 왼쪽 창에 뜨므로 확인하면 됨
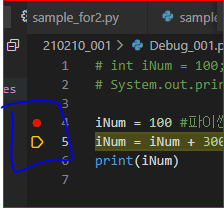
빨간 점은 남고(해당 줄이 실행되었다) 노란색 화살표?가 내려가면서(실행 될 예정이다) 한 줄씩 실행 됨
-> 4번은 이미 수행되었고, 5번은 실행 될 예정이라는 뜻

Local 변수 : 지역 -> LAN선 할 때 L
- special variables :
- iNum: 100 -> 4번 수행의 결과 iNum에 100이 입력된 상태
Globals 변수 : 전역
대입연산자 : 형동등성 원칙 -> 에 입각해 연산 계산
: type이 동등해야 한다
= 의 오른쪽과 왼쪽의 타입이 동등해야 한다.
3.14 + 5
double형 int형
-> 원래는 연산 불가하나 컴파일할 때 컴파일러가 int형인 5를 double형으로 type Casting(형변환)을 해주기 때문에 계산이 가능
연산자 +, - ..
- 단항연산자
- 이항연산자
- 삼항연산자 : 드물다. 자바에서는 4 ? B : C 이런게 삼항연산자
이클립스에서도 디버깅 가능
JavaProject > come.day01 > Exam11.java 9번째 줄(Scanner sc = new Scanner(System.in);에서 노란 줄 위에 포인트 -> Resource leak: 'sc' is never closed : 메모리 누수 -> sc.close();를 해주지 않아서 생긴 경고? 오류?
자바가 너무 어렵다, 잘 모르겠다 하면 디버깅을 하는 것부터 배워서 하나씩 확인해보면 수월함
변수 안에 담긴 내용이 뭔지, 연산 결과가 뭔지 알고 싶으면 Windows > Show View > Expressions

이런 식으로 Add new expression 눌러서 원하는 것을 입력해주면 오른쪽에 변수에 담긴 값이 무엇인지, a%3한 결과값이 무엇인지, a%3==0 의 결과는 False인지, True인지 등등 다 표시해 줌
내가 생각한대로 결과가 나오면 내가 잘 이해하고 있다 라는 뜻
!= 같지 않다. -> =은 항상 오른쪽이다! 라고 외우기
expression : 표현
그러나 디버깅을 할 때는 조사식이라고 부름
디버깅을 하고싶은 부분을 클릭 > Run > Toggle Breakpoint > Run > Debug > Step Over(F6) 하면서 한 줄씩 디버깅

흐름을 예측하고 [F6]을 눌러서 한 줄씩 내 생각과 맞게 나오는지 확인!
sample_list4.py
alist = []
for Temp in range(0, 100) : # Temp에 0~99가 담기고
alist.append(Temp) #alist에 Temp담긴 0~99가 담긴다! [0, 1, .. , 99]
print(alist)
sample_list5
alist = [0, 1, 2, 3, 4]
# Data : 0 1 2 3 4 0 1 2 3 4
# Index : -5 -4 -3 -2 -1 0 1 2 3 4
print(alist[3])
print(alist[-1]) #4
print(alist[-2]) #3
print(alist[-5]) #0
#print(alist[5]) #list index out of range
#print(alist[-6]) #list index out of range3
4
3
0
순방향 한 바퀴, 역방향 한 바퀴로 돌 수 있다.
alist = [] 길이가 5면
Index는 -5 -4 -3 -2 -1 0 1 2 3 4 이렇게 가능
Data는 0 1 2 3 4 0 1 2 3 4
sample_list6.py
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
alist.reverse() #맨 뒤의 값부터 반대로 나옴
print(alist) #55 5 35 3 34 65 23
alist.sort() #순서대로 정렬
print(alist) #
#sort로 정렬해주고 나서 reverse 사용 시 정렬된 상태에서 반대로
alist.reverse() #맨 뒤의 값부터 반대로 나옴
print(alist)[23, 65, 34, 3, 35, 5, 55]
[55, 5, 35, 3, 34, 65, 23]
[3, 5, 23, 34, 35, 55, 65]
[65, 55, 35, 34, 23, 5, 3]
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
alist.insert(2, 77) #34 밀어내고 77이 들어감
print(alist) #23 65 '77' 34 3 35 5 55[23, 65, 34, 3, 35, 5, 55]
[23, 65, 77, 34, 3, 35, 5, 55]
파이썬은 제네릭이 list에 녹아있기 때문에 자바처럼 안해주어도 된다
-> 파이썬은 배열을 마음대로 늘였다, 줄였다, 뒤집었다.. 쉽게 가능!
-> 자바에서는 제네릭을 써서 뒤집을 수 있음
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
Temp = alist.pop() #pop -> 끝에서 하나를 뺏어와서 Temp에 넣음 -> 가장 끝에 있는 값 한개를 끄집어냄 -> 지금처럼 Temp에 저장안해주면 삭제하는 기능만으로 사용 가능!
print(alist) #23 65 34 3 35 5
print(Temp) #55[23, 65, 34, 3, 35, 5, 55]
[23, 65, 34, 3, 35, 5]
55
Temp에 저장하고, Temp를 출력하는 걸 빼면 list의 맨 뒤에 있는 값을 삭제하는 용도로 사용할 수도 있음
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
#Temp = alist.pop() #pop -> 끝에서 하나를 뺏어와서 Temp에 넣음 -> 가장 끝에 있는 값 한개를 끄집어냄 -> 지금처럼 Temp에 저장안해주면 삭제하는 기능만으로 사용 가능!
alist.pop()
print(alist) #23 65 34 3 35 5[23, 65, 34, 3, 35, 5, 55]
[23, 65, 34, 3, 35, 5]
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
alist.extend([1, 99, 200])
print(alist)[23, 65, 34, 3, 35, 5, 55]
[23, 65, 34, 3, 35, 5, 55, 1, 99, 200]
-> 한 개 추가는 append 여러개를 한꺼번에 추가할 때는 extend
추가해줄 값을 다른 리스트에 담아서 extend 해주는 것도 가능
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
alist2 = [1, 99, 200, 300]
alist.extend(alist2)
print(alist)[23, 65, 34, 3, 35, 5, 55]
[23, 65, 34, 3, 35, 5, 55, 1, 99, 200, 300]
clear()를 이용해서 배열 내용 삭제
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
alist.clear()
print(alist)[23, 65, 34, 3, 35, 5, 55]
[]
count(찾을 값 - 예 34)로 list 속에 있는 값 34가 몇개있는지 세어 보기
alist = [23, 65, 34, 3, 35, 5, 55]
print(alist)
alist.append(34) #list에 34가 두개가 됨
print(alist)
print(alist.count(34)) #34가 몇개인지 세어줌 -> 2[23, 65, 34, 3, 35, 5, 55]
[23, 65, 34, 3, 35, 5, 55, 34]
2
sample_list7.py
aList = [[0,1,2],[3,4,5],[7,8,9]]
print(aList) #[[0, 1, 2], [3, 4, 5], [6, 7, 9]]
print(aList[0]) #[0, 1, 2]
print(aList[1]) #[3, 4, 5]
print(aList[2]) #[7, 8, 9]
#4만 출력하기
print(aList[1][1])[[0, 1, 2], [3, 4, 5], [7, 8, 9]]
[0, 1, 2]
[3, 4, 5]
[7, 8, 9]
4
aList = [[0,1,2],[3,4,5],[7,8,9]]
#8을 88로 바꿔보기
aList[2][1] = 88
print(aList)[[0, 1, 2], [3, 4, 5], [7, 88, 9]]
aList = [[0,1,2],
[3,4,5],
[7,8,9]]
print(aList)
aList.extend([10,20,30])
print(aList)[[0, 1, 2], [3, 4, 5], [7, 8, 9]]
[[0, 1, 2], [3, 4, 5], [7, 8, 9], 10, 20, 30]
-> 확장은 되는데 뭔가 이상함..

10 출력하려면?
aList = [[0,1,2],
[3,4,5],
[7,8,9]]
print(aList)
aList.extend([10,20,30])
print(aList)
print(aList[3]) #10
print(aList[4]) #20[[0, 1, 2], [3, 4, 5], [7, 8, 9]]
[[0, 1, 2], [3, 4, 5], [7, 8, 9], 10, 20, 30]
10
20

aList = [[0,1,2],
[3,4,5],
[7,8,9]]
print(aList)
aList.extend([[10,20,30]])
print(aList)
print(aList[3][0]) #10[[0, 1, 2], [3, 4, 5], [7, 8, 9]]
[[0, 1, 2], [3, 4, 5], [7, 8, 9], [10, 20, 30]]
10
sample_tuple1.py
aTuple = '지옥으로 키티'
print(aTuple) #지옥으로 키티
print(aTuple[0]) #지
print(aTuple[6]) #티
print(aTuple[-1]) #티지옥으로 키티
지
티
티
-> 한 글자만 출력하고 싶다? 배열이라고 생각하고 aTuple[0] 이런 식으로!
배열하고 다른 점 : 한 번 만들면 변경, 삭제, 삽입 등 변경 불가
aTuple = '지옥으로 키티' #문자형 튜플
print(aTuple) #지옥으로 키티
print(aTuple[0]) #'지'만 출력
print(aTuple[6]) #'티'만 출력
print(aTuple[-1]) #'티'만 출력
#지를 개로 바꾸고 싶다?
#aTuple[0] = '개' -> 튜플(문자열형 튜플)은 변경 불가(List와 차이점)
#한 번 만들면 변경X, 삭제x, 삽입x
튜플 선언
sample_tuple2.py
#aList = [1, 2, 3] 배열 선언
aTuple = (1, 2, 3) #튜플 선언하는 방법
print(aTuple) #(1, 2, 3) -> 튜플이라는 의미로 ()로 출력됨
print(aTuple[0]) # 배열의 index를 사용해서 하나만 출력할 때는 [] 배열기호를 사용하여 개별적으로 접근
#aTuple[0] = 100 #'tuple' object does not support item assignment -> 튜플 수정 불가(1, 2, 3)
1
aTuple = (1, 2, 3) #튜플 선언하는 방법
print(aTuple)
print(aTuple[1:]) # 슬라이싱 : 1번 자리부터 이후 모두 출력하라 -> (2, 3) 나옴
print(aTuple[1:1]) #()(1, 2, 3)
(2, 3)
()
aTuple = (1, 2, 3) #튜플 선언하는 방법
aTuple2 = (4, 5, 6)
aTuple = aTuple + aTuple2 #추가되는 게 아니고 새로운 (1, 2, 3, 4, 5, 6)이 만들어진 것! - 튜플은 수정 등 불가능하다고 했음
print(aTuple) #(1, 2, 3, 4, 5, 6)
print(aTuple2) #(4, 5, 6)(1, 2, 3, 4, 5, 6)
(4, 5, 6)
aTuple = (1, 2, 3) #튜플 선언하는 방법
aTuple2 = (4, 5, 6)
aTuple = aTuple + aTuple2
print(aTuple) #(1, 2, 3, 4, 5, 6)
print(aTuple[0:0]) #()
print(aTuple[0:1]) #(1,) -> 0번째 값부터 1번째 값 앞부분까지 출력돼서 1,까지 나오는듯?
print(aTuple[0:2]) #(1, 2)
print(aTuple[1:3]) #(2, 3)
print(aTuple[1:3]) #(2, 3)
print(aTuple[2:4]) #(3, 4)
print(aTuple[2:-1]) #(3, 4, 5)
print(aTuple[2:-2]) #(3, 4)
print(aTuple[-5:-1]) #(2, 3, 4, 5)(1, 2, 3, 4, 5, 6)
()
(1,)
(1, 2)
(2, 3)
(2, 3)
(3, 4)
(3, 4, 5)
(3, 4)
(2, 3, 4, 5)
aTuple = (1, 2, 3) #튜플 선언하는 방법
aTuple2 = (4, 5, 6)
aTuple = aTuple + aTuple2[1:]
#aTuple2[1:] -> (5, 6)
print(aTuple) #(1, 2, 3, 5, 6)(1, 2, 3, 5, 6)
-> 이렇게 슬라이싱 해서 4를 버리고 붙여주는 것도 가능
sample_tuple3.py
튜플에 한해서 등분 괄호를 생략할 수 있다!!
배열은 [ ] 를 생략해서 적어줄 수 없지만 튜플은 가능하다.
따라서, 변수 = 1, 2, 3 이렇게 입력해줬다면 튜플!!!!!
aTuple = 0, 1, 2
print(aTuple)(0, 1, 2)
aTuple = 0, '할룽', '여보세용', 3.14
# int str str float
print(aTuple)(0, '할룽', '여보세용', 3.14)
-> 자료형에 상관없이 다 들어감 : 자바로 치면 object형 ..
aTuple이라는 튜플 하나에 들어가있는 값들의 자료형이 뭔지 출력해보자
aTuple = 0, '할룽', '여보세용', 3.14
# int str str float
print(aTuple)
print(type(aTuple[0]))
print(type(aTuple[1]))
print(type(aTuple[3]))(0, '할룽', '여보세용', 3.14)
<class 'int'>
<class 'str'>
<class 'float'>
-> 이렇게 각각 다른 자료형이라 하더라도 마구잡이로 다 집어넣기가 가능함
'욤'만 출력해보자
aTuple = 0, '할룽', '여보세욤', 3.14
# int str str float
print(aTuple)
print(type(aTuple[0]))
print(type(aTuple[1]))
print(type(aTuple[3]))
print(aTuple[2][3]) #'욤'만 출력
print(aTuple[2][-1]) #'욤'만 출력(0, '할룽', '여보세욤', 3.14)
<class 'int'>
<class 'str'>
<class 'float'>
욤
욤
aTuple = 0, '할룽', '여보세욤', 3.14
# int str str float
print(aTuple)
print(aTuple[0]) #0 출력
print(aTuple[1]) # '할룽' 출력
print(aTuple[3]) # 3.14 출력
print(aTuple[2][3]) #'욤'만 출력
print(aTuple[2][-1]) #'욤'만 출력(0, '할룽', '여보세욤', 3.14)
0
할룽
3.14
욤
욤
sample_tuple4.py
Temp = range(0, 10)
Temp2 = 1, 2
print(Temp) # range(0,10)
print(Temp2) # (1, 2)range(0, 10)
(1, 2)
aTuple = 3, 4, 5
print(aTuple)
aTuple2 = aTuple * 3
print(aTuple)
print(aTuple2)(3, 4, 5)
(3, 4, 5)
(3, 4, 5, 3, 4, 5, 3, 4, 5)
튜플에 *를 해보자
aTuple = 3, 4, 5
print(aTuple) #(3, 4, 5)
aTuple2 = aTuple * 3
print(aTuple) #(3, 4, 5)
print(aTuple2) #(3, 4, 5, 3, 4, 5, 3, 4, 5)
print(len(aTuple)) #3
print(len(aTuple2)) #9
(3, 4, 5)
(3, 4, 5)
(3, 4, 5, 3, 4, 5, 3, 4, 5)
3
9
-> 튜플에 곱하기를 해주면 자가증식? 함..
sample_tuple5.py
aTuple = tuple(range(1, 10)) #range 1~9까지 만드는데 tuple로 만들어져서 aTuple에 저장됨
print(aTuple) #(1, 2, 3, 4, 5, 6, 7, 8, 9)(1, 2, 3, 4, 5, 6, 7, 8, 9)
aTuple = tuple(range(0, 100, 13))
print(aTuple)
(0, 13, 26, 39, 52, 65, 78, 91)
-> 리스트도 똑같이 이런식으로 만들어줄 수 있음
aTuple = tuple(range(0, 100, 13))
print(aTuple)
aList = list(range(0, 100, 13))
print(aList)
(0, 13, 26, 39, 52, 65, 78, 91)
[0, 13, 26, 39, 52, 65, 78, 91]
-> 튜플은 ( ) 로, 리스트는 [ ] 로 나온다
aTuple = '지옥으로 키티'
aTuple = aTuple * 3
print(aTuple) #지옥으로 키티지옥으로 키티지옥으로 키티지옥으로 키티지옥으로 키티지옥으로 키티
-> 문자열도 마찬가지로 ! *를 해주면 튜플 속 내용이 그만큼 더해져서 나옴
<시퀀스 계열>
** 시퀀스 하부 계열에 리스트, 튜플, range, str 이 있음
--> 이들 시퀀스 계열은 차례대로 다닥다닥 붙어있다.
--> 공통적으로 사용할 수 있는 것 : in, not in, +, *

in : 어떤 값이 존재하는지 알고 싶을 때 사용
aTuple = tuple(range(10)) # 0 ~ 9
print(aTuple) #(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
print(5 in aTuple) #aTuple 안에 5가 있는가? True
print(10 in aTuple) #aTuple 안에 10가 있는가? False(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
True
False
-> 시퀀스 계열(리스트, 튜플, range, str)에서 모두 사용 가능하다
print(10 in range(10)) #False
print(10 not in range(10)) #TrueFalse
True
aRange = range(2, 20, 5) # 2~19까지 5씩 증가
print(aRange[0])
print(aRange[3])
#17을 수정할 수 있을까? 불가능
#aRange[3] = 10 #'range' object does not support item assignment2
7
aRange = range(2, 20, 5) # 2~19까지 5씩 증가
print(aRange[0])
print(aRange[3])
aTuple = tuple(aRange)
print(aTuple)2
17
(2, 7, 12, 17)

시퀀스는 총 7가지, 그 중 우리가 배운 리스트, 튜플, range, 문자열 중 리스트만 수정이 가능하고
나머지 튜플, 레인지, 문자열은 수정이 불가능
sample_dic1.py
dictionary -> 1:1로 대응되는 것들을 한 세트씩 :으로 묶어서 넣어주기!
aDict = {'이름':'홍길동', '나이': 50, 10 : "10만원"}
print(aDict) # {'이름': '홍길동', '나이': 50}
print(type(aDict)) # <class 'dict'>
print(aDict['이름']) # 홍길동
print(aDict['나이']) # 50
print(aDict[10]) #10만원{'이름': '홍길동', '나이': 50}
<class 'dict'>
홍길동
50
10만원
자바를 배울 때 DB도 했었음
- ID : identifier 식별자 -> 개체와 개체의 차이를 알고 구분? 하는것이 식별하다 라고 한다.
-> DB에서는 ID를 Key라고 함 -> Key 값은 겹치면 안된다
-> 이름은 식별자(ID), key가 될 수 없다 -> 동명이인이 있을 수 있기 때문 -> 고유하지 않음
-> 한국 사람을 구분하기 위해 만든 것 : 주민등록번호
-> 생체로 본다면 id로 사용할 수 있는 것 : DNA, 지문
-> DNA를 통해 identity를 찾아낸다
sample_dic2.py
aDict1 = dict(test = 100, spring=200)
aDict2 = dict({'test' : 100, 'spring' : 200})
aDict3 = {'test' : 100, 'spring' : 200}
aDict4 = dict([('test', 100), ('spring', 200)])
print(aDict1)
print(aDict2)
print(aDict3)
print(aDict4){'test': 100, 'spring': 200}
{'test': 100, 'spring': 200}
{'test': 100, 'spring': 200}
{'test': 100, 'spring': 200}
-> 전부 다 가능하지만 3번째 것만 외우자!
sample_dic3.py
aDict = {'이름':'홍길동', '나이': 50, 10 : "10만원"}
print(aDict) #{'이름': '홍길동', '나이': 50, 10: '10만원'}
print(aDict.keys()) #dict_keys(['이름', '나이', 10])
print(aDict.values ()) #dict_values(['홍길동', 50, '10만원'])
del aDict['나이'] #'나이'라는 key 삭제
print(aDict) #{'이름': '홍길동', 10: '10만원'}
print('나이' in aDict) #False{'이름': '홍길동', '나이': 50, 10: '10만원'}
dict_keys(['이름', '나이', 10])
dict_values(['홍길동', 50, '10만원'])
{'이름': '홍길동', 10: '10만원'}
False
<함수>
function : C, C++, python
Method : 자바
Procedure : 파스칼, 어셈블리어
-> 다 같은 말이나 파이썬에서는 function, 함수라고 부른다.
폴더 = 디렉터리 같은 말
sample_fun.py
함수 spring을 만들어보자
자바였으면
void spring() {
}이렇게 적어줬을 것
파이썬은 아래와 같음
def spring() :
print('지옥으로 키티')
-> 실행해도 아무것도 나오지 않음 -> 함수는 만들었으나 실행하지 않았기 때문에
-> def : define 정의하다의 약자
print('시작')
def spring() :
print('지옥으로 키티')
print('종료')시작
종료
spring()를 적어줘야 안에 내용이 실행되어서
지옥으로 키티 가 출력됨
-> 자바와 호출 방법 동일
메소드를 만들 때 자바의 경우 아래와 같이 적어줌
반환자료형/void 메소드이름(인자/인수/매개변수) {
return 반환자료형과 일치하는 변수/상수/없음;
}
그러나 파이썬은 자료형을 써주지 않음
- 자료형, 중괄호는 안 쓰지만 : 과 들여쓰기(tab)가 있음
- 함수 선언 시 def 적어주어야 함
def spring(Num) :
print('-----------------------------')
print(Num)
print('-----------------------------')
spring(100)
spring(200)100
200
sample_fun3.py
def spring(Num1, Num2) :
return Num1 + Num2
Temp = spring(3, 5) #type은 실행될 때 인자 값으로 3, 5를 넣으므로 그 때 정의됨
print(Temp)8
-> 함수 정의 시 def
-> 중괄호가 없는 대신 : 와 들여쓰기를 한다
-> spring이 어떤 값을 return하느냐에 따라 Temp의 자료형이 결정됨
sample_fun4.py
def spring(Num1, Num2) :
return Num1 + 1000, Num2 + 2000 # 튜플로 반환됨
Temp = spring(100, 200)
print(Temp)(1100, 2200)
def spring(Num1, Num2) : #반환 자료형을 언급하지 않음, 인자의 자료형도 마찬가지
return Num1 + 1000, Num2 + 2000 # 튜플로 반환됨
Temp = spring(100, 200)
print(Temp)
RetVal1, RetVal2 = spring(111, 222) #111과 222를 각각 받기 때문에 RetVal1, RetVal2 모두 int형
print(RetVal1) #111
print(RetVal2) #222(1100, 2200)
1111
2222
p.99
#p.99 두번째 예제 : 여러 개의 인수를 입력받아서 계산을 하는 함수 선언
def mydef01() : #인수 없는 함수 선언
i = 10
j = 20
print(i + j)
mydef01()
def mydef02(i, j) : #인수 두 개를 받아서
print(i + j) #두 인수를 합하고 결과 출력
mydef02(10, 20)
#계산할 숫자를 두 개를 입력합니다.
def mydef03(i, j, p) : # 세 개의 인수를 받는 함수 선언
if p == '+' :
print(i + j)
elif p == '-' :
print(i - j)
elif p == '*' :
print(i * j)
elif p == '/' :
print(i / j)
n = int(input("첫 번째 숫자를 입력합니다. ")) # 사용자가 첫 번째 숫자를 입력 -> 문자형으로 입력되므로 int형으로 캐스팅
m = int(input("두 번째 숫자를 입력합니다. ")) # 사용자가 두 번째 숫자를 입력
p = input("연산자를 입력하세요(+, -, *, /) ") # 사용자가 연산자를 입력
mydef03(n, m, p) #첫 번째, 두 번째, 연산자를 입력 받아서 함수 호출
30
30
첫 번째 숫자를 입력합니다. 10
두 번째 숫자를 입력합니다. 20
연산자를 입력하세요(+, -, *, /) +
30
폴더
210210_002
Spring02.py
def Spring_Function() :
print("지금은 마지막 수업시간입니다.")
Spring01.py
Spring_Function()에러 : name 'Spring_Function' is not defined
-> Spring_Function 라는 함수는 Spring02.py 안에 선언된 함수이므로 Spring01.py에서는 사용 불가능
import 시키면 사용 가능하다
import Spring02
Spring02.Spring_Function()지금은 마지막 수업시간입니다.
다시 Spring02.py로 와서 변수 선언
Num = 1004
String = '지옥으로 키티'
def Spring_Function() :
print("지금은 마지막 수업시간입니다.")
Spring01.py에서 사용
import Spring02
Spring02.Spring_Function()
print(Spring02.Num)
print(Spring02.String)지금은 마지막 수업시간입니다.
1004
지옥으로 키티
-> import : 현재 파일에 있지 않는, 다른 파일에서 선언한 함수, 변수 등을 갖다 쓸 수 있음
갖다쓸 때는 파일 이름에 .py를 붙이지 않고 이름만 적어주면 됨
근데 매번 Spring02. 이렇게 해서 호출하기 번거로움 -> as 사용
import Spring02 as S
#Spring02.Spring_Function() -> as S 했으면 Spring02. 으로 사용불가
import Spring02 #이것도 같이 적어주면 S도 가능, Spring02로도 가능
Spring02.Spring_Function()
S.Spring_Function()
print(S.Num)
print(S.String)지금은 마지막 수업시간입니다.
지금은 마지막 수업시간입니다.
1004
지옥으로 키티
Spring02.py 파일의 가장 첫 번째 줄에 print(******시작*******) 입력해보기
print("******시작*******") # python은 ""와 ''의 구분 없이 사용 가능
def Spring_Function() :
print("지금은 마지막 수업시간입니다.")
******시작*******
-> print 출력 됨
Spring01.py 실행시키면
*******시작*******
지금은 마지막 수업시간입니다.
지금은 마지막 수업시간입니다.
-> 함수로 호출하지 않은 *******시작******* 이 가장 먼저 출력되었음..!
Spring02.py 그러면 맨 마지막 부분에 *******끝*******도 넣어줘보자
print("*******시작*******") # python은 ""와 ''의 구분 없이 사용 가능
Num = 1004
String = '지옥으로 키티'
def Spring_Function() :
print("지금은 마지막 수업시간입니다.")
print("*******끝*******")*******시작*******
*******끝*******
다시 Spring01.py를 실행시켜보면
*******시작*******
*******끝*******
지금은 마지막 수업시간입니다.
지금은 마지막 수업시간입니다.
--> 호출하지 않은 끝 이라는 것도 먼저 출력됨...
-> 그 이유는 import Spring02를 하는 순간 Spring02.py의 모든 코드를 가지고와서 실행이 되기 때문!!
-> import Spring02와 import Spring02 as S 이렇게 두 번을 import를 시켜 주어도
*******시작*******
*******끝*******
은 한 번만 출력되는 것을 알 수 있음!
Spring01.py를 이렇게 수정해보자
print('1')
import Spring02 as S #import 시키게 되면 Spring02의 모든 코드 다 들고옴
print('2')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('3')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('4')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
Spring02.Spring_Function()
S.Spring_Function()
print(S.Num)
print(S.String)1
*******시작*******
*******끝*******
2
3
4
지금은 마지막 수업시간입니다.
지금은 마지막 수업시간입니다.
1004
지옥으로 키티
-> 보면 Spring02를 여러 번 import 해주었지만 시작, 끝은 처음 import시킨 순간에 한 번만 출력되는 것을 알 수 있음!

이때까지는 210210_002라는 같은 폴더 내에 존재하는 파일끼리 import 시켰는데,
다른 디렉토리에 있는 함수도 import 시키면 사용이 가능하다.
- 상위 디렉토리에서 가져오는 것은 복잡!! -> 다음 시간에!
- 같은 디렉토리에 있으면 위에서 배운 것처럼 그냥 import 시켜서 쓰면 되고
- 하부 디렉토리에서 가져오기 : from
-> 210210_002폴더 아래에 Sub 폴더 만들고 그 안에 Test.py 파일 만들기

Test.py
def Spring2():
print('스프링2가 호출됩니다.')
Spring01.py
print('1')
import Spring02 as S #import 시키게 되면 Spring02의 모든 코드 다 들고옴
print('2')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('3')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('4')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
Spring02.Spring_Function()
S.Spring_Function()
print(S.Num)
print(S.String)
from Sub import Test #하부 디렉토리 Sub 폴더에서 Test.py를 import시켜 사용하겠다
Test.Spring2() #하부 디렉토리 Sub > Test.py 내의 함수 Spring2()를 호출1
*******시작*******
*******끝*******
2
3
4
지금은 마지막 수업시간입니다.
지금은 마지막 수업시간입니다.
1004
지옥으로 키티
스프링2가 호출됩니다.
이 경우에도 as를 이용해 더 짧고, 간단하게 함수를 호출할 수 있도록 해주자
print('1')
import Spring02 as S #import 시키게 되면 Spring02의 모든 코드 다 들고옴
print('2')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('3')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('4')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
Spring02.Spring_Function()
S.Spring_Function()
print(S.Num)
print(S.String)
from Sub import Test as T
T.Spring2()1
*******시작*******
*******끝*******
2
3
4
지금은 마지막 수업시간입니다.
지금은 마지막 수업시간입니다.
1004
지옥으로 키티
스프링2가 호출됩니다.
-> 마찬가지로 T로만 호출하지 않고 Test로도 호출하고 싶으면
from Sub import Test 도 같이 적어주면 됨
print('1')
import Spring02 as S #import 시키게 되면 Spring02의 모든 코드 다 들고옴
print('2')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('3')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
print('4')
import Spring02 #이미 앞에서 import시켰기 때문에 영향 X
Spring02.Spring_Function()
S.Spring_Function()
print(S.Num)
print(S.String)
from Sub import Test as T
from Sub import Test
T.Spring2()
Test.Spring2()1
*******시작*******
*******끝*******
2
3
4
지금은 마지막 수업시간입니다.
지금은 마지막 수업시간입니다.
1004
지옥으로 키티
스프링2가 호출됩니다.
스프링2가 호출됩니다.
-> 이렇게 하면 호출을 Test.Spring2()로 해도 되고 T.Spring02()로 해도 됨
-> 그렇지만 import 시켜서 코드 전체를 들고오는 것은 한 번만 됨!
프로그램은 왜 이렇게 파일 단위로 쪼개져 있는가?
- 회사에 들어가서 일을 할 때, 파일 단위로 소스 관리
ex) 자동차를 만드는 프로세스를 만든다
- 엔진 담당 파일, body 담당 파일, ... 등 파일을 따로 만들어 놓고 완성되면 -> 같이 묶어서 조립?
- 메서드도 메서드를 조립해서! 사용
- 자바의 경우에는 보통 클래스 단위로 쪼개서 관리
★ 타이핑 : 영타 150타 정도면 충분함 - 긴 문장 치는 연습하기!
정보처리기사(국가공인자격증)는 빨리 딸수록 좋다!! -> 나중에 따면 되지 XX -> 개발자로 취업해서 일을 해도 정처기가 있어야 경력 인정이 된다
하지만 정보처리기사가 있는가, 없는가보다 코딩 실력이 우선이다. 정보처리 기사 자격증은 있는데 코딩은 못한다? 탈락
Q : 제네릭 써봤어요?
A : 네? -> '아 얘는 그게 뭔지 모르는구나' -> 나머지 면접 시간에 다른 얘기만 하다가 Bye~
두 지원자가 있을 때, 실력이 비슷하다 -> 그 때는 정보처리기사 있는 사람이 유리
이력서 --> 이걸 보고 면접 볼 사람을 추린다
- 맞춤법 중요 -> 문서 작성할 일이 많기 때문에
- 1년 과정이면 프로필, 자소서 포함 보통 30장 정도 만든다 -> 100장 쓴다? No. 30으로 낮추라. 너무 많으면 안 본다
-> 차라리 30장 정도로 추린 후 나머지는 면접관 수만큼 책으로 제본해서 들고 가든지(이력서에 다 표현을 못해서 30장 정도로 추렸는데 제본해서 들고왔다 혹시 보여드려도 되겠느냐)
- 포트폴리오 : 우리가 배우고, 프로젝트 한 것을 한 프로젝트 당 1~2 바닥으로 문서화한 것
-> 발표 자료(ppt), 보고서 성의있게 신경 써서 만들기!, 핵심적 내용 설명, 베껴서 쓴 것은 티가 나고, 갖다 버린다
- 물건을 살 때, 포장이 중요한 것처럼 -> 취업을 할 때는 그 포장 역할을 하는 게 이력서고, 포장을 벗겼을 때 나오는 물건, 즉 알맹이는 면접
첫 관문 입사 -> 20년을 이걸로 먹고 살 수 있어야 한다
'프로그래밍 > 파이썬' 카테고리의 다른 글
| [파이썬] 1일차 - 개발환경 설정, 기초 (0) | 2021.02.09 |
|---|---|
| [파이썬 예습] 유투브 코딩 1시간만에 배우기 - 파이썬(ft. 실리콘밸리 엔지니어) (0) | 2021.02.06 |