[지난 주]
스칼라 부속질의 -> 비/상관 다 가능
인라인 뷰 부속질의 -> 비상관
중첩 부속질의 -> 비/상관 다 가능
3. 중첩질의 - WHERE 부속질의
- 비교 연산자 : 부속질의가 반드시 단일 행, 단일 열을 반환해야 하며, 아닐 경우 질의를 처리할 수 없음.
질의 4-15 평균 주문금액 이하의 주문에 대해서 주문번호와 금액을 보이시오.
select orderid, saleprice
from orders
where saleprice <= (select avg(saleprice)
from orders);saleprice <= ave(saleprice) from orders
값(모든 값) 전체 평균(값1개)
-> 비상관
질의 4-16 각 고객의 평균 주문금액보다 큰 금액의 주문 내역에 대해서 주문번호, 고객번호, 금액을 보이시오.
-> 고객별
select orderid, custid, saleprice
from orders od
where saleprice > (select avg(saleprice)
from orders os
where od.custid = os.custid);saleprice를 비교를 하긴 하는데
각 고객의 평균 saleprice가 그 고객의 saleprice가 큰지를 따져야 하니까
고객 번호가 같은 것끼리 각각 비교해야 함(custid 별로 비교) -> 상관
-> group by로 풀어도 됨
- IN, NOT IN -> 비상관 -> 부속절먼저 계산 후 메인절 계산함
IN 연산자 : 주직의 속성 값이 부속질의에서 제공한 결과 집합에 있는지 확인(check)하는 역할
부속질의 결과 다중 행을 가질 수 있음
주질의는 WHERE 절에 사용되는 속성 값을 부속질의의 결과 집합과 비교해 하나라도 있으면 참이 됨
NOT IN : IN과 반대로 값이 존재하지 않으면 참이 됨
질의 4-17 대한민국에 거주하는 고객에게 판매한 도서의 총판매액을 구하시오.
select sum(saleprice)
from orders
where custid in (select custid
from customer
where address like '대한민국%');customer에서 custid를 쭉 만들어 낼건데 adress가 '대한민국'인 custid가 쭉쭉 나올 것
이 custid들 중에 존재하는 custid가 있으면 그 custid의 sum(saleprice)를 구해 줌
-> 부속질의 결과 주소가 대한민국인 custid가 여러개 나옴 -> orders의 custid와 비교하기 위해 in 사용
- ALL, SOME(=ANY)
-> in : 여러개 이 중에 너랑 같은게 있니? 이런 느낌
-> ALL : 여기있는 것 전체보다 > 큰지? < 작은지?
-> SOME(=ANY) : 여기있는 것 보다 > 크거나 < 같거나 한게 하나라도 있니?
ALL은 모두, SOME(ANY)은 어떠한(최소한 하나라도)이라는 의미를 가짐
구문 구조
scalar_expression {비교연산자(= | <> | != | > | >= | !> | > | <= | !<)}
{ALL | SOME | ANY] (부속질의)
질의 4-18 3번 고객이 주문한 도서의 최고 금액 보다 더 비싼 도서를 구입한 주문의 주문번호와 금액을 보이시오.
select orderid, saleprice
from orders
where saleprice > ALL (select max(saleprice)
from orders
where custid = 3);-> ALL을 빼도 됨
- EXISTS, NOT EXISTS -> 항상 상관을 쓴다.
데이터의 존재 유무를 확인하는 연산자
주질의에서 부속질의로 제공된 속성의 값을 가지고 부속질의에 조건을 만족하여 값이 존재하면 참이 되고, 주질의는 해당 행의 데이터를 출력함
NOT EXISTS의 경우 이와 반대로 동작함
구문구조
WHERE [NOT] EXISTS (부속질의)
질의 4-19 EXISTS 연산자로 대한민국에 거주하는 고객에게 판매한 도서의 총 판매액을 구하시오.
select sum(saleprice) /* 총 판매액을 구하는데 */
from orders od
where exists (select * /* 별도의 조건을 여기서 달아줌 */
from customer cs /* address가 대한민국인 custid가 주문한 saleprice의 합(주절, 부속절 연결) */
where cs.custid = od.custid
and address like '대한민국%');adress가 대한민국인 custid가 속한 행을 모두 출력하는데
orders에서 그 행이 속한 saleprice의 총합을 구한다.
1) 조인
2) where 절에 address로 검색/필터링
[연습문제 풀이] -> 어떤 질의인지 알아내고 이걸 문제로 해서 다시 질의 작성해보기.
4. 부속질의에 관한 다음 SQL문을 수행해보고 어떤 질의에 대한 답인지 설명하시오.
(1)
select custid, (select address
from Customer cs
where cs.custid=od.custid) "address",
sum(saleprice) "total" /* 스칼라 부속질의 */
from orders od
group by od.custid;
--주문 테이블에서 고객 id별(고객별)로 주소와 구매가 합계를 구해서
-- custid, address, sum(saleprice)를 나타내시오.
-- 조인 후 where절 써주면 됨
-- orders 테이블에서 스칼라 부속질의를 통해서 orders와 custid를 상관시켜서 address를 끼워넣은 것
-- -> 주문이 있는 고객에 대해 그 고객별로 custid의 address와 그 고객의 saleprice 합계를 구함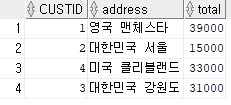
(2)
select cs.name, s
from (select custid, avg(saleprice) s /* 인라인 뷰 부속질의 */
from orders
group by custid) od, customer cs /* 주문을 한 고객별 평균금액을 구해서 고객이름, 평균금액을 나타내시오 */
where cs.custid=od.custid;

-> Q. 고객의 이름과 고객별 주문 금액의 평균을 나타내시오
select name, avg(saleprice)
from customer, orders
where customer.custid = orders.custid
group by name;
(3)
select sum(saleprice) "total"
from orders od
where exists (select * /* 중첩 부속질의 */
from customer cs
where custid <= 3 and cs.custid = od.custid);
-- 주문에서 saleprice 합계를 구할건데,
-- 고객 테이블에서 custid가 3보다 작은 고객의 총 판매 금액을 구하라.
-- 조인 후 where에서 조건 걸어주고 풀어도 됨
Q. 고객번호가 3이하인 고객들의 구매금액의 총합을 구하여라
select sum(saleprice)
from orders
where custid <= 3;
03. 뷰 : 뷰의 생성, 수정, 삭제
-> 프로그램에서는 화면, GUI 이런 느낌 / DB 오라클에서는 보여주기 테이블=짝퉁/논리적(<->물리적) 테이블
물리적 테이블 : book, customer .. 실제 존재하는 테이블 등
- 뷰(view) : 하나 이상의 테이블을 합하여 만든 가상의 테이블
-> 원래 테이블에 있는 데이터들을 원하는 부분만 (연결하는 등 해서) 만든 가상의 테이블을 저장
- 장점(목적)
- 편리성 : 미리 정의된 뷰를 일반 테이블처럼 사용할 수 있기 때문에 편리함. 또 사용자가 필요한 정보만 요구에 맞게 가공하여 뷰로 만들어 쓸 수 있음
- 재사용성 : 자주 사용되는 질의를 뷰로 미리 정의해 놓을 수 있음
- 보안성 : 각 사용자별로 필요한 데이터만 선별하여 보여줄 수 있음. 중요한 질의의 경우 질의 내용을 암호화 할 수 있음
ex) 테이블에 이름, 나이, 주소, 주민번호가 있는 경우
- 주민번호만 제외한 이름, 나이, 주소만 나타내는 view를 작성 -> 보안성 !
ex) 100명이 각각 1000개씩 글을 작성 -> 총 10만개의 데이터
- 100명의 데이터를 게시한 1000개씩의 글은 빼고 ID만 뷰로 작성해서 관리
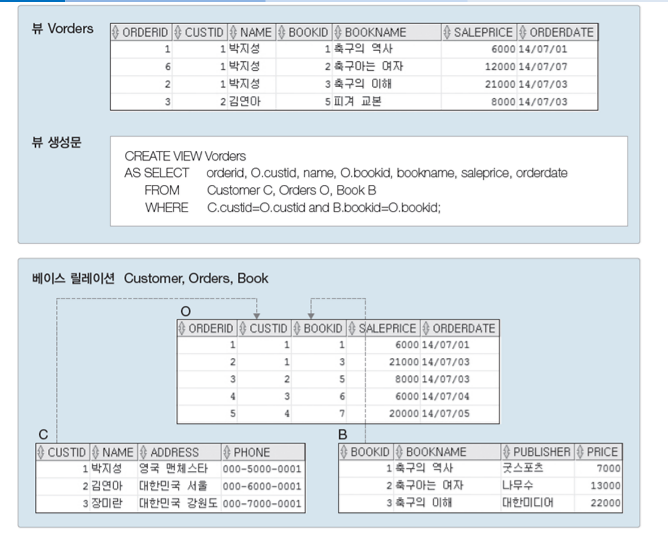
ex) Book, Orders, Customer를 조인해서 테이블로 만들어 두면 만들어둔 뷰에서 구매자 이름으로만 검색해도
주문한 책의 이름, 가격 등을 을 바로 찾을 수 있다.(원래는 세개를 조인해서 검색했어야 함)
1. 뷰의 생성
- 기본 문법
CREATE VIEW 뷰이름 [(열이름) [ ,...n])]
AS select 문
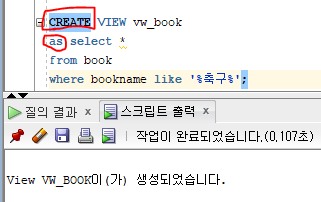
- Book 테이블에서 '축구'라는 문구가 포함된 자료만 보여주는 뷰
select *
from book
where bookname like '%축구%';
- 위 SELECT 문을 이용해 작성한 뷰의 정의문
질의 4-20 주소에 '대한민국'을 포함하는 고객들로 구성된 뷰를 만들고 조회하시오.
단, 뷰의 이름은 vw_Customer로 한다.
-- 뷰 생성
create view vw_customer
as select *
from customer
where address like '%대한민국%';
-- 결과 확인
select *
from vw_customer;-> table에 있는 데이터를 참조(연결)한 데이터 -> 원본이 바뀌면 뷰도 그에 따라 바뀐다.

질의 4-21 Orders 테이블에 고객이름과 도서이름을 바로 확인할 수 있는 뷰를 생성한 후, '김연아' 고객이 구입한 도서의 주문번호, 도서이름, 주문액을 보이시오.
-> 검색할 것이 고객이름, 도서이름, 주문번호, 도서이름, 주문액 이걸 나타내려면
select od.custid, cs.name, od.orderid, bk.bookname, od.saleprice
from customer cs, orders od, book bk
where cs.custid = od.custid
and od.bookid = bk.bookid;
이걸 뷰로 생성
create view vw_orders (orderid, custid, name, bookid, bookname, saleprice, orderdate) /* 괄호 안에 속성들은 view의 칼럼 이름들임 생략해도 되고 칼럼 이름을 뷰에서는 다른걸로 새로 지정해 줄 수 있음 */
as select od.orderid, od.custid, cs.name, od.bookid, bk.bookname, od.saleprice, od.orderdate
from customer cs, orders od, book bk
where cs.custid = od.custid
and od.bookid = bk.bookid;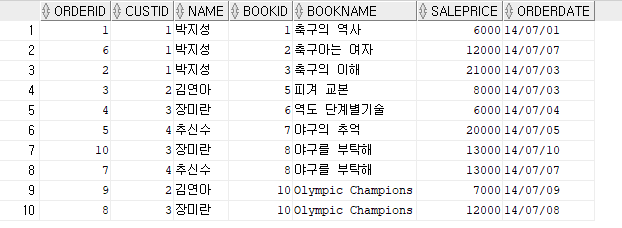
-> 괄호 안에 속성 이름을 바꿔줄 수 있다.
create or replace view vw_orders ("주문번호", "고객번호", name, bookid, bookname, saleprice, orderdate) /* 괄호 안에 속성들은 view의 칼럼 이름들임 생략해도 되고 칼럼 이름을 뷰에서는 다른걸로 새로 지정해 줄 수 있음 */
as select od.orderid, od.custid, cs.name, od.bookid, bk.bookname, od.saleprice, od.orderdate
from customer cs, orders od, book bk
where cs.custid = od.custid
and od.bookid = bk.bookid;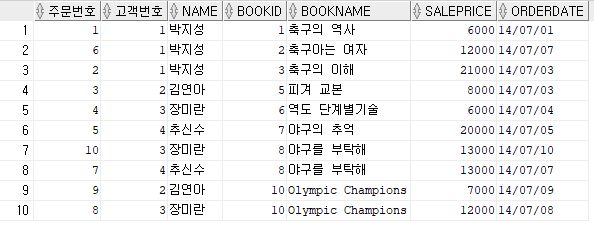
뷰에서 김연아 고객이 구입한 도서의 주문번호, 도서이름, 주문액 보이기
select orderid, bookname, saleprice
from vw_orders
where name = '김연아';
2. 뷰의 수정
- 기본 문법
CREATE OR REPLACE VIEW 뷰이름 [(열이름 [,...n])] -> 없으면 새로 만들고 있으면 덮어써라
AS select 문
질의 4-22 [질의 4-20]에서 생성한 뷰 vw_Customer는 주소가 대한민국인 고객을 보여준다.
이 뷰를 영국을 주소로 가진 고객으로 변경하시오. phone 속성은 필요 없으므로 포함시키지 마시오.
create or replace view vw_customer (custid, name, address)
as select custid, name, address
from customer
where address like '%영국%';view vw_customer를 수정
<결과 확인>
select * from vw_customer;

3. 뷰의 삭제
- 기본 문법
DROP VIEW 뷰이름 [,...n];
질의 4-23 앞서 생성한 뷰 vw_Customer를 삭제하시오.
DROP VIEW vw_Customer;
<결과 확인>
select * from vw_customer;

6. 다음에 해당하는 뷰를 작성하시오. 데이터베이스는 마당서점 데이터베이스를 이용한다.
(1) 판매가격이 20,000원 이상인 도서의 도서번호, 도서이름, 고객이름, 출판사, 판매가격을 보여주는 highorders 뷰를 생성하시오.
create view highorders
as select book.bookid, book.bookname, customer.name, book.publisher, orders.saleprice
from book, customer, orders
where book.bookid = orders.bookid
and customer.custid = orders.custid
and saleprice >= 20000;
-- bookid는 book에도 있고 order에도 있으니까 book.bookid처럼 정확한 위치를 지정해줘야 한다.
(2) 생성한 뷰를 이용하여 판매된 도서의 이름과 고객의 이름을 출력하는 SQL문을 작성하시오.
select bookname, name
from highorders;
(3) highorders 뷰를 변경하고자 한다. 판매가격 속성을 삭제하는 명령을 수행하시오. 삭제 후 (2)번 SQL 문을 다시 수행하시오.
create or replace view highorders
as select book.bookid, book.bookname, customer.name, book.publisher
from book, customer, orders
where book.bookid = orders.bookid
and customer.custid = orders.custid
and saleprice >= 20000;
2번 SQL문 다시 수행

결과 동일
04. 인덱스(Index) : DB의 목차 -> 테이블의 목차 -> column에 순서번호를 매기겠다 -> 정렬(sort)
-> 내부적으로 column에 순서를 만들어서 가지고 있겠다.
- 데이터베이스의 물리적 저장
- 인덱스와 B-tree : 자료구조 -> 검색 알고리즘
- 오라클 인덱스
- 인덱스의 생성
- 인덱스의 재구성과 삭제
1. 데이터베이스의 물리적 저장

- 실제 데이터가 저장되는 곳은 보조기억장치 : 하드디스크, SSD, USB 메모리 등
- 가장 많이 사용되는 장치는 하드디스크


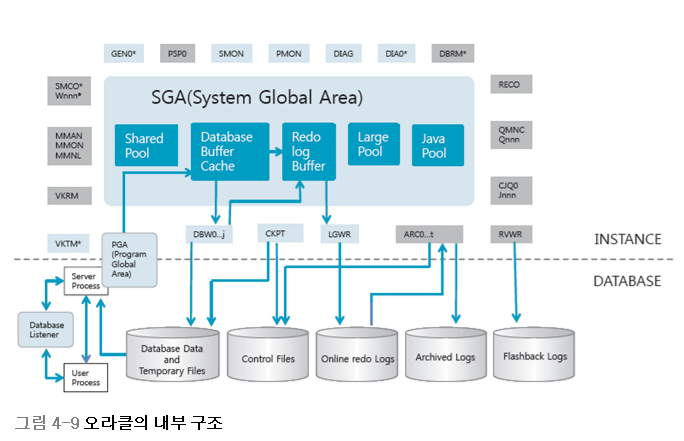
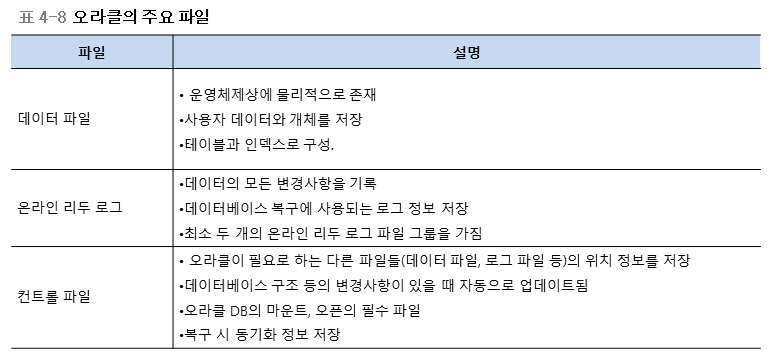
2. 인덱스와 B-tree
ex) 전화번호부 찾을 때 3등분이 되어있다고 했을 때 1번 부분에는 성씨가 가~다, 2 라~사, 3 아~하 이렇게 나눠져 있으면 내가 찾고자 하는 사람이 나길동이면 1번인 가~다에서 찾는다.
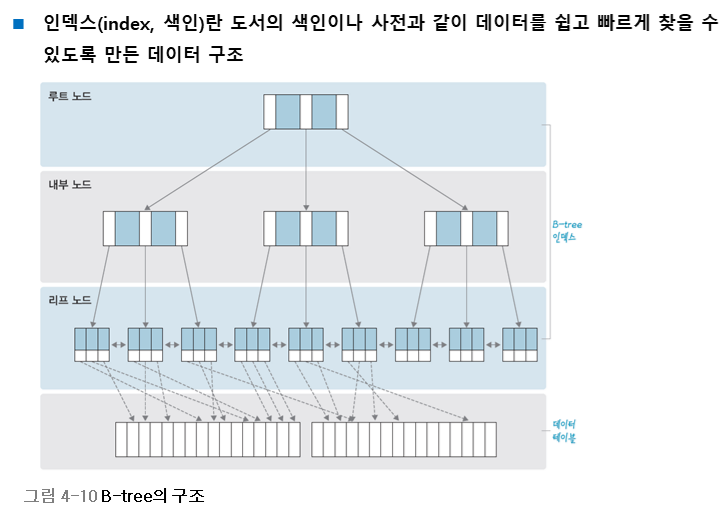
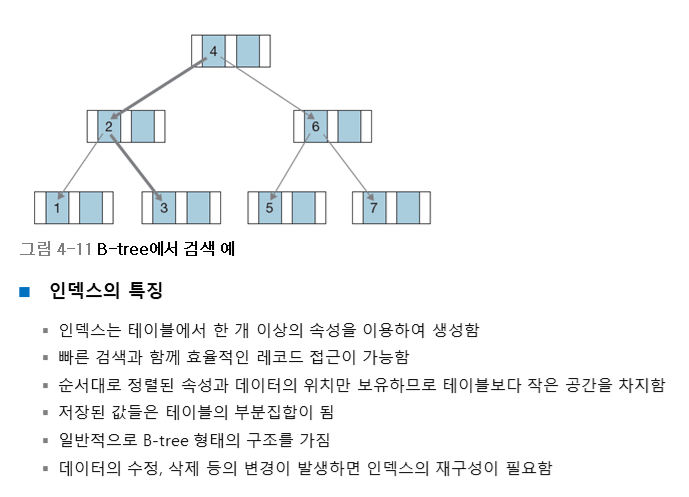
3.1 오라클 B-tree 인덱스
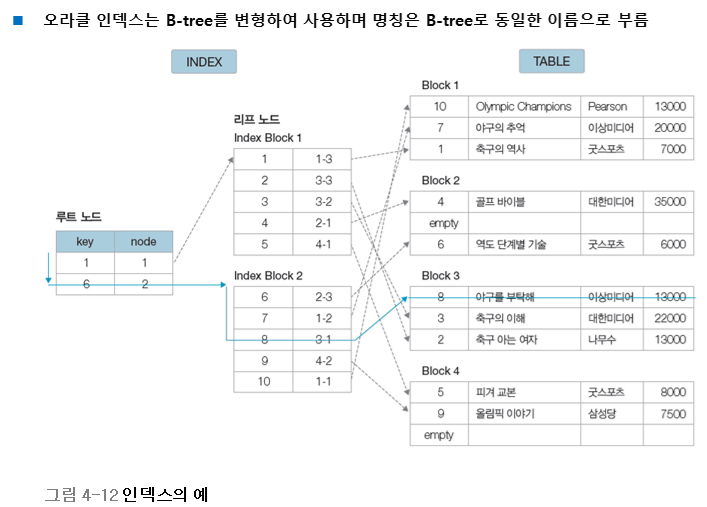

4. 인덱스의 생성
-> column에 순번을 매긴다(기본 : 오름차순) : 검색을 빠르게 하려고 한다.
-> bookname에 index를 걸었다 -> why? 눈에 보이는 효과는 X, 내부적으로 index가 걸려있음.
-> 책 이름은 순서가 뒤죽박죽 되어 있어도 ㄱㄴㄷ..순으로 index 순서를 매겨놓음
-> select * from book where bookname like '%축구%'; 이런 경우처럼 조건을 bookname으로 검색을 하면
-> 결과 값은 동일, 그러나 index가 걸려있으면 검색 속도가 훨씬 빠르다.
-> bookname으로 검색하지 않고 bookid 등 다른 것으로 하면 효과 없다.
-> 만약 이름 순서대로 인덱스를 부여했는데 신입 회원이 추가되거낭 이름이 수정되었다 -> 인덱스가 다 바뀐다 -> 입력이 자주 일어나는 데이터 -> 이름 순으로 다시 인덱스 재부여 해야하니까 오래 걸림(과부하) : INSERT, UPDATE
-> 데이터가 자주 바뀌는 것은 INDEX를 걸면 안 됨 but 삭제(DELETE)의 경우 중간에 빠져도 순서는 유지되므로 재정렬 하지 X
1
2
3
4
5
6
7
8
-> 순서는 바뀌지 않아서 상관은 없는데(1->2->7->8) 중간이 뻥 비어서 7번부터 앞으로 당겨서 3번부터 다시 번호 부여하고싶으면 -> REBUILD
-> 주로 SELECT () <-에 들어갈 것에 index를 부여하라(insert, update가 자주 되지 않는)
- 인덱스 생성 시 고려사항
- 인덱스는 WHERE 절에 자주 사용되는 속성이어야 함
- 인덱스는 조인에 자주 사용되는 속성이어야 함
- 단일 테이블에 인덱스가 많으면 속도가 느려질 수 있음(테이블 당 4~5개 정도 권장)
- 속성이 가공되는 경우 사용하지 않음
- 속성의 선택도가 낮을 때 유리함(속성의 모든 값이 다른 경우)
- 인덱스의 생성 문법
CREATE [REVERSE] | [UNIQUE] INDEX 인덱스이름]
ON 테이블이름 (컬럼 [ASC | DESC] [{, 컬럼 [ASC | DESC]} ...])[;]
질의 4-24 Book 테이블의 bookname 열을 대상으로 비 클러스터 인덱스 ix_Book을 생성하라.
create index ix_book on book (bookname);

질의 4-25 Customer 테이블의 name 열을 대상으로 클러스터 인덱스 cix_Customer를 생성하시오.
CREATE INDEX ix_Book2 ON Book(publisher, price);-> select ~ from ~ where publisher ~ and price ~;처럼 두개 한꺼번에 지정했을 때는 두개를 한번에 검색할 때만 효과있다.
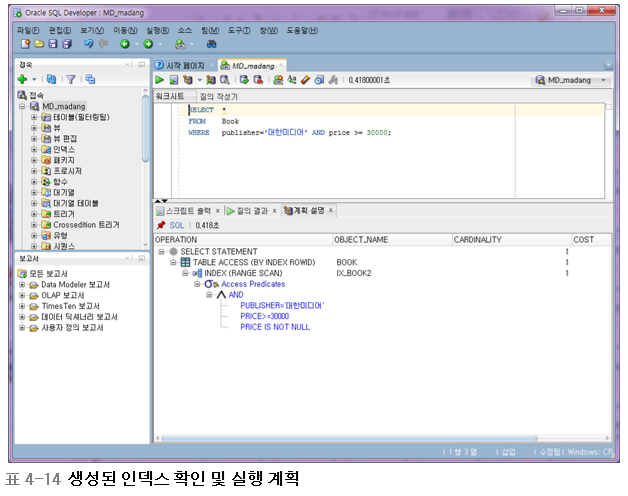
5. 인덱스의 재구성과 삭제
- 인덱스의 재구성은 ALTER INDEX 명령을 사용함
- 생성 문법
ALTER [REVERSE] [UNIQUE] INDEX 인덱스이름
[ON {ONLY} 테이블이름 {컬럼이름 [{, 컬럼이름} ...])] REBUILD[;]
질의 4-26 인덱스 ix_Book을 재생성하시오.
ALTER INDEX ix_book rebuild;

- 삭제 문법
DROP INDEX 인덱스이름
질의 4-27 인덱스 ix_Book을 삭제하시오.
DROP index ix_book;

13. [마당서점 데이터베이스 인덱스] 마당서점 데이터베이스에서 다음 SQL 문을 수행하고 데이터베이스가 인덱스를 사용하는 과정을 확인하시오.
(1) 다음 SQL 문을 수행해본다.
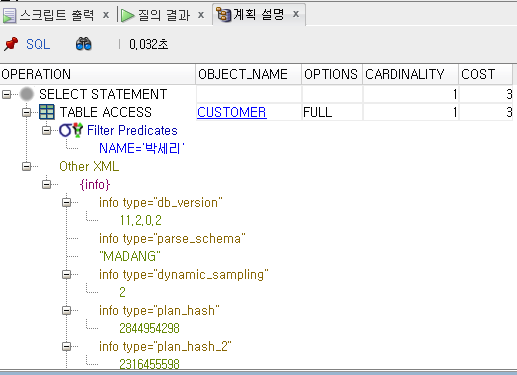
SELECT name FROM Customer WHERE name LIKE '박세리';

(2) 실행 계획을 살펴본다. 실행 계획은 [F10]키를 누른 후 [계획 설명] 탭을 선택하면 표시된다.
CARDINALITY - 결과의 행 -> 박세리니까 1개만 나온다.
COST - 비용 -> 숫자가 낮은 것이 좋다.

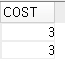
(3) Customer 테이블에 name으로 인덱스를 생성하시오. 생성 후 (1)번의 질의를 다시 수행하고 실행 계획을 살펴보시오.
create index ix_name on customer (name);
인덱스명 테이블명(컬럼명)


(4) 같은 질의에 대한 두 가지 실행 계획을 비교해보시오.
COST가 3 -> 1로 낮아졌다.
cf) select name from customer; -> where 뒤에 조건을 name으로 걸어줘야 COST가 낮아진다.
(5) (3)번에서 생성한 인덱스를 삭제하시오.
Drop index ix_name;

요약
1. 내장 함수
2. 부속질의
3. 뷰
4. 인덱스
5. B-tree
6. 오라클 인덱스의 종류
'프로그래밍 > 자바(java) 융합개발자 2차' 카테고리의 다른 글
| [취성패] 자바 배우기 - 8일차 일지(PL/SQL) (0) | 2020.12.23 |
|---|---|
| [취성패] 자바 배우기 - 7일차 일지(PL/SQL) (0) | 2020.12.23 |
| [취성패] 자바 배우기 - 5일차 일지 2(부속질의 - 스칼라, 인라인 뷰, 중첩질의1) (0) | 2020.12.18 |
| [취성패] 자바 배우기 - 5일차 일지(SQL 고급 - 내장함수) (0) | 2020.12.18 |
| [취성패] 자바프로그래밍 - 4일차 학습일지(SQL-데이터 정의어) (0) | 2020.12.17 |