트리거(-> 방아쇠) : 자동 실행, DB에서 많이 씀
- 원래 우리가 Select ~ ~~ 작성한 다음 Ctrl + Enter를 해서 실행을 시켜주거나 실행문 작성해야 하는데
자동으로 시간마다 작동되는 그런 느낌
ex) 장비 온도 측정 시 -> 3분 마다 측정(app에서 측정)한다고 치면 온도가 계속 바뀔거고 DB도 계속 Update가 될 것
dev 1 24.4 > 24.3 > .. > 24.0
dev 2 23.5
dev 3 17.7
-> 이건 변한 결과 현재 값만 나오게 됨 -> 근데 나는 변화 이력을 남기고 싶다? -> History를 기록할 테이블을 하나 더 만든다
History 테이블
1 dev 1 24.4 -> 복합키로 잡아 줌
2 dev 1 23.5
3 dev 1 17.7
-> 이 테이블에는 update될 때 마다 로그 남기는 것처럼 기록이 된다.
=> 트리거는 Update가 발생 시(when, if) 쿼리를 날린다 -> 여기서는 History 테이블에 insert 쿼리를 날린다(발동한다)
insert
delete -> 요 세개에서 많이 쓰고
select : ex) 누가 내 계좌를 조회했다. 언제, 누가 조회 했는지 이력을 남기는 등
cf) 시퀀스 : 자동 순번 생성
4. TRIGGER(트리거) [생략]
- 서브 프로그램 단위의 하나인 TRIGGER는 테이블, 뷰, 스키마 또는 데이터베이스에 관련된 PL/SQL 블록(또는 프로시저)으로 관련된 특정 사건(Event)이 발생될 때마다 묵시적(자동)으로 해당 PL/SQL 블록이 실행됩니다
- TRIGGER는 데이터베이스 내에 오브젝트로서 저장되어 관리됩니다.
- 그리고 TRIGGER 자체는 사용자가 지정해서 실행을 할 수 없으며, 오직 TRIGGER 생성시 정의한 특정 사건(Event)에 의해서만 묵시적인 자동실행(Fire)이 이루어집니다
- TRIGGER 를 생성하려면 CREATE TRIGGER, 수정하려면 ALTER TRIGGER, 삭제하려면 DROP TRIGGER 의 권한이 필요합니다. 또한 DATABASE 전체의 TRIGGER 조작은 ADMINISTER DATABASE TRIGGER 시스템 권한이 필요합니다.
- TRIGGER 에 대한 정보는 USER_OBJECTS, USER_TRIGGERS, USER_ERRORS 딕셔너리들을 조회하면 알 수 있습니다.
- TRIGGER를 이루는 TRIGGER 몸체(실행부)에 TCL 명령, 즉 COMMIT, ROLLBACK, SAVEPOINT 명령이 포함될 수 없다는 점도 꼭 기억하셔야 합니다.
2) 주요 TRIGGER 유형
ex) 온도라는 것에 24.8이 저장되어 있었다.
24.8 25.0
old -> new : 이렇게 값이 변하면 다른 곳에 담아 뒀다가 old 24.8을 이력을 남길 테이블에 기록하고 new인 25.0를 기존 온도에 저장(덮어씀)
(1) 단순 DML TRIGGER
- BEFORE TRIGGER
: 테이블에서 DML 이벤트를 TRIGGER하기 전에 TRIGGER 본문을 실행합니다
- AFTER TRIGGER
: 테이블에서 DML 이벤트를 TRIGGER한 후에 TRIGGER 본문을 실행합니다
- INSTEAD OF TRIGGER
: TRIGGER문 대신 TRIGGER 본문을 실행하며, 다른 방법으로는 수정이 불가능한 뷰에 사용됩니다
- 문장 TRIGGER / 행 TRIGGER
문장 TRIGGER는 영향을 받는 행이 전혀 없더라도 TRIGGER가 한 번은 실행됩니다. 문장 TRIGGER는 TRIGGER 작업이 영향을 받는 행의 데이터 또는 TRIGGER 이벤트 자체에서 제공하는 데이터에 종속되지 않은 경우에 유용합니다.
행 TRIGGER는 테이블이 TRIGGER 이벤트의 영향을 받을 때마다 실행되고, TRIGGER 이벤트의 영향을 받는 행이 없을 경우에는 실행되지 않습니다. 행 TRIGGER는 영향을 받는 행의 데이터나 TRIGGER 이벤트 자체에서 제공하는 데이터에 TRIGGER 작업이 종속될 경우에 유용합니다.
행 TRIGGER 로 생성하려면 FOR EACH ROW 라는 구절을 사용하면 됩니다.
create sequence ID_SEQUENCE
START WITH 1
INCREMENT BY 1;
create or replace ID_SEQUENCE_TRIGGER
BEFORE INSERT
ON CONTENTS_TABLE
REFERENCING NEW AS NEW
FOR EACH ROW
BEGIN
SELECT ID_SEQUENCE.nextval INTO :NEW.CONTENTS_ID FROM dual;
END;
/
DROP TRIGGER CON_STORAGE_STATUS_TRG;
CREATE OR REPLACE TRIGGER CON_STORAGE_STATUS_TRG
AFTER INSERT OR UPDATE
ON CON_STORAGE_STATUS FOR EACH ROW
BEGIN
INSERT INTO CON_STORAGE_HISTORY(
CON_ID,
TEMP_THIS,
TEMP_SET,
DEFROST_TIME,
DEFROST_CYCLE,
TEMP_GAP,
TEMP_SUB,
PRESSURE_HIGH,
PRESSURE_LOW,
POWER_ON,
LAMP_ON,
MANUAL_DEFROST_ON,
NATURAL_DEFROST_ON,
DEFROST_TYPE,
WRITE_TIME
)
VALUES
(
:NEW.CON_ID,
:NEW.TEMP_THIS,
:NEW.TEMP_SET,
:NEW.DEFROST_TIME,
:NEW.DEFROST_CYCLE,
:NEW.TEMP_GAP,
:NEW.TEMP_SUB,
:NEW.PRESSURE_HIGH,
:NEW.PRESSURE_LOW,
:NEW.POWER_ON,
:NEW.LAMP_ON,
:NEW.MANUAL_DEFROST_ON,
:NEW.NATURAL_DEFROST_ON,
:NEW.DEFROST_TYPE,
:NEW.WRITE_TIME
);
END;
출처 : https://cafe.naver.com/busanit2018db
(2) 혼합 TRIGGER (11g 부터 추가됨)
혼합 TRIGGER는 여러 가지 TRIGGER를 하나로 만든 것으로 마치 PL/SQL 의
패키지와 비슷한 개념입니다
- 혼합 TRIGGER는 DML TRIGGER여야 하며 테이블이나 뷰에 정의해야 합니다.
- 혼합 TRIGGER의 본문은 PL/SQL에서 작성한 혼합 TRIGGER 블록이어야 합니다.
- 혼합 TRIGGER 본문에는 초기화 블록이 포함될 수 없으므로 예외 섹션이 있을 수 없습니다.
- 한 섹션에서 발생하는 예외는 해당 섹션에서 처리되어야 합니다. 다른 섹션에서 처리하도록 권한을 이전할 수 없습니다.
- : OLD 및 :NEW는 선언, BEFORE STATEMENT 또는 AFTER STATEMENT 섹션에 나타날 수 없습니다.
- BEFORE EACH ROW 섹션만 :NEW 값을 변경할 수 있습니다.
- FOLLOWS 절을 사용하지 않으면 혼합 TRIGGER의 실행 순서가 일정하지 않습니다.
(3) DML이 아닌 TRIGGER
- DDL 이벤트 TRIGGER
DML TRIGGER와 거의 동일하지만 TRIGGER 를 활용하여 DDL 작업을 하는 것만 다릅니다.
– 데이터베이스 이벤트 TRIGGER
데이터베이스 이벤트 TRIGGER란 데이터베이스 내에서 생기는 일들을 관리하기 위해서 생성하는 TRIGGER 입니다. 사용자 관련 이벤트가 있고 시스템 관련 이벤트가 있으며 아래와 같습니다.
- 유저 이벤트 TRIGGER:
사용자가 발생시키는 작업에 TRIGGER를 생성합니다.
CREATE, ALTER 또는 DROP
로그온 또는 로그오프
- 데이터베이스 또는 시스템 이벤트 TRIGGER:
데이터베이스 전체에 영향을 주는 작업에 TRIGGER를 생성합니다.
데이터베이스 종료 또는 시작
발생한 특정 오류 (또는 임의의 오류)
4) TRIGGER 생성
CREATE [OR REPLACE] TRIGGER trigger_name
timing
event1 [ OR event2 OR event3 … ]
ON {table_name|view_name|SCHEMA|DATABASE}
[REFERENCING OLD AS old | NEW AS new]
[FOR EACH ROW [WHEN ( condition ) ] ]
trigger_body
5) TRIGGER 관리
- 활성화/비활성화 하기
ALTER TRIGGER trigger_name DISABLE | ENABLE ;- 특정 테이블에 속한 TRIGGER의 활성화/비활성화
ALTER TABLE table_name DISABLE | ENABLE ALL TRIGGERS ;- TRIGGER 수정 후 다시 컴파일하기
ALTER TRIGGER trigger_name COMPILE ;- TRIGGER 삭제
DROP TRIGGER trigger_name ;- TRIGGER 조회하기
USER_TRIGGERS 를 조회하면 됩니다.
- TRIGGER 관련 권한들
• 스키마에서 TRIGGER를 생성, 변경 및 삭제할 수 있는 권한:
– GRANT CREATE TRIGGER TO SCOTT ;
– GRANT ALTER ANY TRIGGER TO SCOTT;
– GRANT DROP ANY TRIGGER TO SCOTT ;
• 데이터베이스에서 TRIGGER를 생성할 수 있는 권한:
– GRANT ADMINISTER DATABASE TRIGGER TO SCOTT ;
• EXECUTE 권한 (TRIGGER가 실행하는 스키마에 포함되지 않은 객체를 참조하는 경우)
6) Trigger 예제 : 교재 참고
8장. INDEX(인덱스)
- INDEX는 특정 column에 대해서 오름차순, 내림차순 등으로 정렬해서 눈에 보이지 않지만 1, 2, 3, .. 숫자를 붙이는 것
- 오라클은 B - TREE 구조로 이루어져 있다
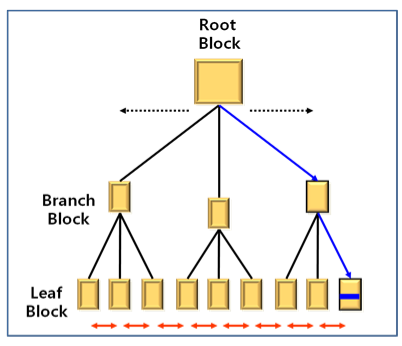
(1) UNIQUE INDEX
ㄴ> 만들 때 유의
ID같은 곳에는 붙일 수 있으나 name 이런 데는 붙일 수 없다. -> 동일값이 올 수 없기 때문(동명이인 있을 수 있으므로 이름에는 안됨) -> 기본키나 중복을 가지지 못하는 열에서는 붙일 수 있다.
가능하면 UNIQUE INDEX를 붙인다 -> 속도가 더 빠르기 때문!


(2) NON-UNIQUE INDEX
ex) 이름으로 검색할 때 등, 많이 쓰임

(3) Function Based INDEX(FBI – 함수기반 인덱스)
* INDEX Suppressing Error 란 ?

(4) DESCENDING INDEX (내림차순 인덱스)

(5) 결합 인덱스 (Composite INDEX)

ename, sex -> 복합인덱스 -> 복합키
기본키 일땐 순서가 필요 없는데 이 경우
순서가 필요

CASE1(sex, name)으로 했을 때와 CASE2(name, sex)로 했을 때가 다르다.
where name = and sex =
ex) 100개의 데이터가 있다.
CASE1
남자 / 여자로 거른다 -> 50명으로 걸러짐 -> 거기서 Smith를 찾는다 -> 2명 나옴
CASE2
이름으로 검색 -> 2명으로 걸러짐 -> 성별로 거름 -> 2명 나옴
-> 1단계에서 98개를 거를 수 있었으므로 이게 훨씬 낫다.
=> 많이 걸러지는 걸 앞에 두고 보편적인 것을 뒤에 둔다!
2) BITMAP INDEX(생략) -> 가장 빠르다
-> BINARY(이진) -> 흑백 (1, 0)으로 흑백을 나타내겠다.
0~255로 색 농도 조절 -> 그레이스케일

CREATE BITMAP INDEX IDX_EMP_SEX_BIT
ON EMP(SEX) ; -> 옵션(남, 녀)이 적을 수록 성능이 좋아진다.
데이터가 추가될 경우에는 ?

5. 인덱스의 주의사항
1) DML에 취약하다
(1) INSERT 작업 시 인덱스에 발생하는 현상 - INDEX Split 현상이 발생한다! -> insert, update가 많으면 쓰면 안된다
(2) Delete – Index 데이터는 지워지지 않는다 !
(3) Update – Delete + Insert 현상이 발생한다
2) 타 SQL 실행에 악영향을 줄 수 있다 !
1) DML에 취약하다
(1) INSERT 작업 시 인덱스에 발생하는 현상
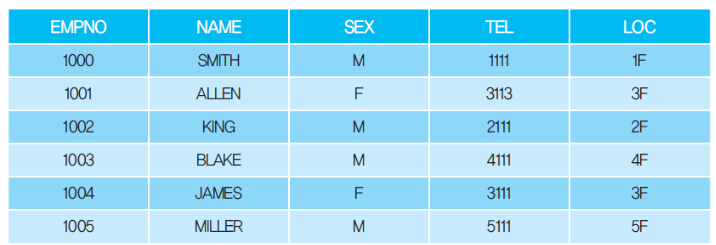
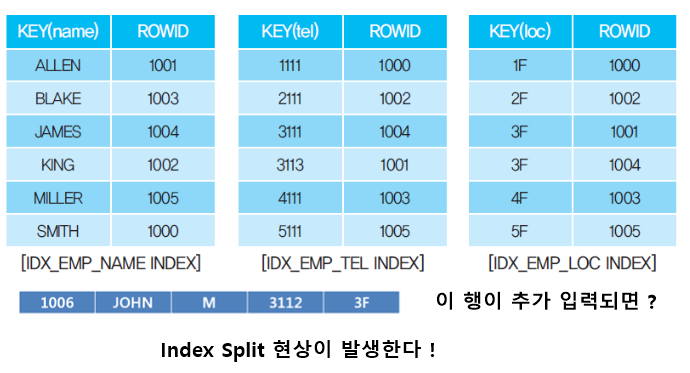
6. 인덱스 관리 방법
1) 인덱스 조회하기 [생략]
set line 200
col table_name for a10
col column_name for a10
col index_name for a20
SELECT table_name,column_name,index_name
FROM user_ind_columns
WHERE table_name='EMP2' ;
SELECT table_name, index_name
FROM user_indexes
WHERE table_name='DEPT2';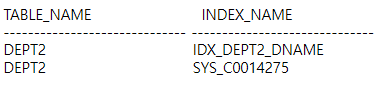
2) 사용 여부 모니터링 하기 -> 내가 만든 index를 사용하고 있는지 여부 확인
ALTER INDEX IDX_EMP_ENAME MONITORING USAGE ; -- 모니터링 시작하기ALTER INDEX IDX_EMP_ENAME NOMONITORING USAGE ; -- 모니터링 중단하기-- 사용 유무 확인하기
SELECT index_name, used
FROM v$object_usage
WHERE index_name='IDX_EMP_ENAME';
단 위 내용은 자신이 만든 인덱스만 확인 가능함.
전체 인덱스를 확인하려면 교재 P.393의 방법을 참고하세요
3) INDEX Rebuild 하기
DELETE된 자료가 있을 때 자리를 옮기지 않음(1234567 -> 12 67 ) -> Rebuild하면 (1234)로
DML 작업은 인덱스의 밸런싱 상태를 흩트려서 성능에 나쁜 영향을 줌.
주기적으로 점검해서 밸런싱 상태를 좋게 유지해야 함.
Index Rebuild 관련 실습은 교재 P.395를 참고
7. Invisible Index(인비저블 인덱스) - 11g New Feature
- 인덱스를 만들었는데 사용 중지를 하고싶다 -> Drop해서 지워도 되지만 지우지 않고 잠시 사용을 중지하는 것
[생략]
CREATE INDEX idx_emp_sal ON emp(sal) ;Index created.
SELECT table_name,index_name,visibility
FROM user_indexes
WHERE table_name = 'EMP' ;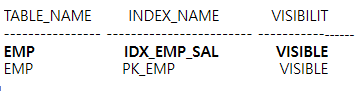
ALTER INDEX idx_emp_sal INVISIBLE ;Index altered.
SELECT table_name, index_name, visibility
FROM user_indexes
WHERE table_name = 'EMP' ;
- 다시 상태를 VISIBLE로 변경해서 자동으로 사용하게 만들기

ename > '0'; -> 이름을 오름차순으로 정렬 (ename에 index가 걸려있어야 사용 가능)
= order by name(DB가 부담을 느낌)과 같은 효과지만 성능이 월등하게 높다
ㄴ> 인덱스가 걸려있지 않으면 이걸 써야 함
소프트웨어에서는 가성비가 중요하다!
[SETP-UP 1] 다양한 인덱스 활용 방법들 [생략]
1) 인덱스를 활용하여 정렬한 효과를 내는 방법

2) 인덱스를 활용하여 최소값(MIN) / 최대값(MAX)을 구하는 방법
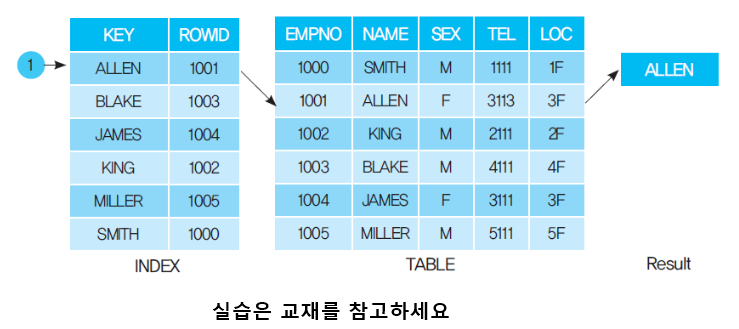
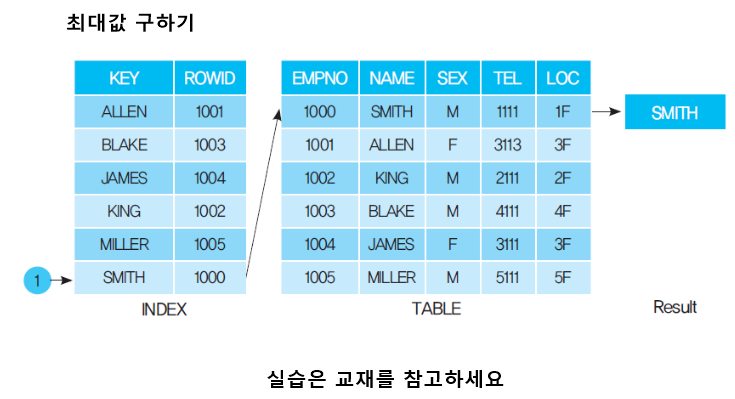
[ STEP-UP 2 ] ROWID 에 대해서 알아봅시다. [생략]
SELECT ROWID, empno, ename
FROM emp
WHERE empno=7902 ;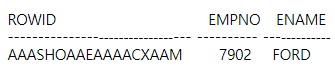

'프로그래밍 > 자바(java) 융합개발자 2차' 카테고리의 다른 글
| [자바 기초] 12일차 일지 - 데이터베이스 프로그래밍(JSP웹, DB프로그래밍, Apache Tomcat 설치하기, 8080 포트 오류 해결하기) (0) | 2020.12.30 |
|---|---|
| [자바 기초] 11일차 일지 2 - 데이터베이스 프로그래밍(이클립스 설치, JAVA) (0) | 2020.12.29 |
| [자바 기초] 10일차 일지 2 - Oracle PL/SQL 이어서(ORACLE SUBPROGRAM) (0) | 2020.12.28 |
| [자바 기초] 10일차 일지 1 - 6. 데이터 모델링 (0) | 2020.12.28 |
| [취성패] 자바 배우기 - 9일차 일지(PL/SQL 제어문, 커서) (0) | 2020.12.24 |